
Scrapi MCP Server
by
Provides an MCP server that enables scraping of web pages through ScrAPI, delivering HTML or Markdown output for downstream processing.
Scrapi MCP Server Overview
What is Scrapi MCP Server about?
Scrapi MCP Server exposes ScrAPI’s scraping capabilities via the Model Context Protocol, allowing clients to request a URL and receive either the raw HTML or a Markdown rendering of the page. It is designed for scenarios where sites employ bot detection, captchas, or geolocation restrictions.
How to use Scrapi MCP Server?
-
Install via NPX (recommended):
{ "mcpServers": { "scrapi": { "command": "npx", "args": ["-y", "@deventerprisesoftware/scrapi-mcp"], "env": { "SCRAPI_API_KEY": "<YOUR_API_KEY>" } } } }Add the above block to your
claude_desktop_config.jsonor any MCP‑compatible client configuration. -
Docker alternative:
docker run -i --rm -e SCRAPI_API_KEY=<YOUR_API_KEY> deventerprisesoftware/scrapi-mcp -
Cloud SSE endpoint (no API‑key forwarding):
https://api.scrapi.dev/sse. -
Calling tools:
scrape_url_html– input:url(string); returns HTML.scrape_url_markdown– input:url(string); returns Markdown.
Key Features
- Two tool endpoints (
scrape_url_htmlandscrape_url_markdown). - Handles sites with bot detection, captchas, and geo‑restrictions.
- Optional API key lifts the default limit of one concurrent call and 20 free calls per day.
- Available as a Docker image, NPX package, and hosted SSE cloud server.
- Simple integration with Claude Desktop and other MCP clients.
Use Cases
- Bypassing anti‑scraping measures: Retrieve page content from sites that block typical HTTP clients.
- Data extraction pipelines: Feed raw HTML to parsers or convert Markdown for text‑centric analysis.
- Geolocation‑specific scraping: Access region‑locked content without managing proxies.
- Rapid prototyping: Use the NPX command within a local development environment or in Claude Desktop.
- Server‑less integration: Connect to the cloud SSE endpoint for low‑maintenance deployments.
FAQ
-
Do I need an API key? No, but without it you are limited to one concurrent request and 20 free calls per day.
-
How do I set my API key? Pass it via the
SCRAPI_API_KEYenvironment variable in the NPX or Docker command, or include it in theenvsection of your MCP configuration. -
Can I run the server locally without Docker? Yes, the NPX package downloads and runs the server directly.
-
Is there a hosted version? Yes, the cloud SSE endpoint at
https://api.scrapi.dev/sse. -
What output formats are supported? HTML and Markdown, selected by the respective tool.
-
Will the cloud server accept my API key? Currently the cloud endpoint does not forward an API key; use the local NPX/Docker server for authenticated calls.
Scrapi MCP Server's README
![]()
ScrAPI MCP Server
![]()


MCP server for using ScrAPI to scrape web pages.
ScrAPI is your ultimate web scraping solution, offering powerful, reliable, and easy-to-use features to extract data from any website effortlessly.
Tools
-
scrape_url_html- Use a URL to scrape a website using the ScrAPI service and retrieve the result as HTML. Use this for scraping website content that is difficult to access because of bot detection, captchas or even geolocation restrictions. The result will be in HTML which is preferable if advanced parsing is required.
- Input:
url(string) - Returns: HTML content of the URL
-
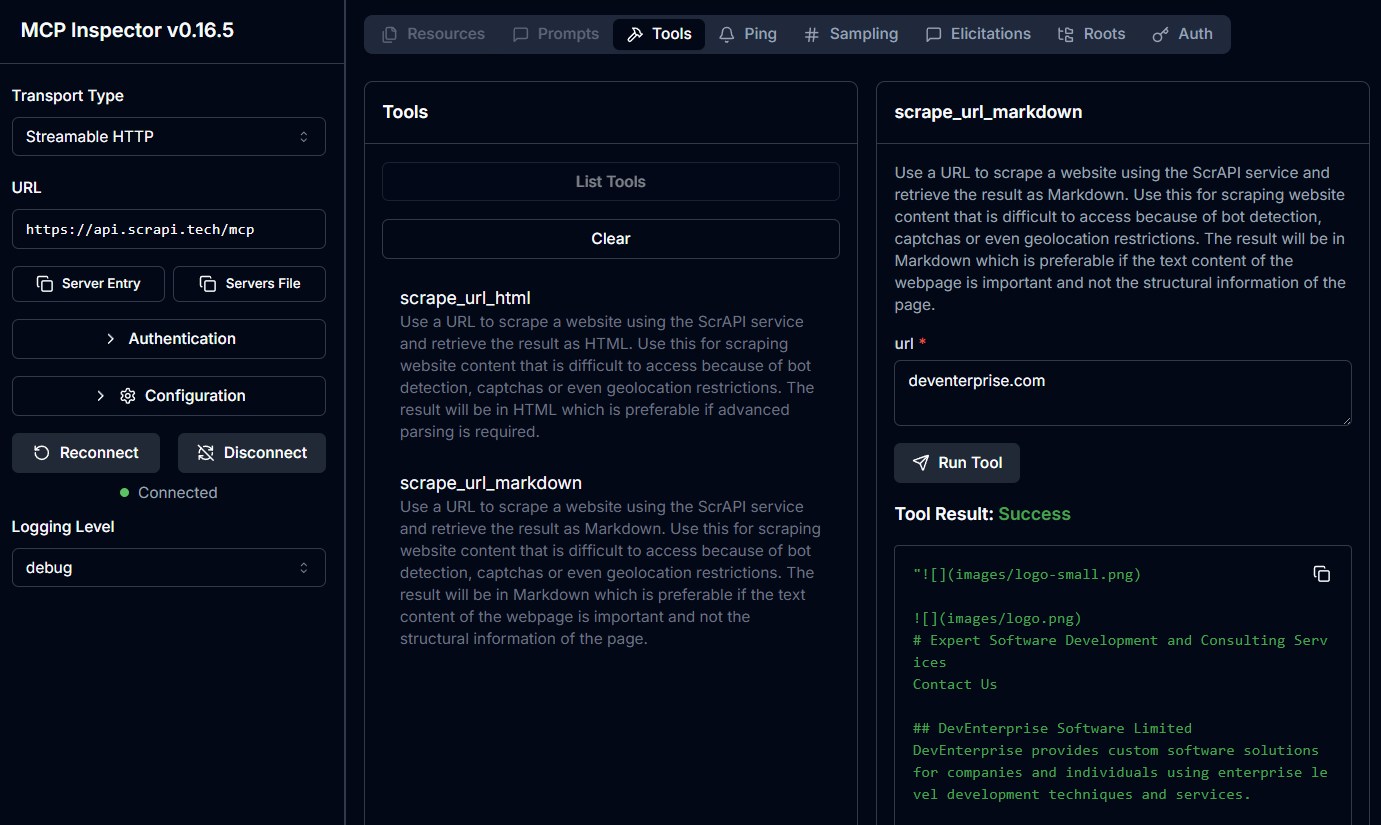
scrape_url_markdown- Use a URL to scrape a website using the ScrAPI service and retrieve the result as Markdown. Use this for scraping website content that is difficult to access because of bot detection, captchas or even geolocation restrictions. The result will be in Markdown which is preferable if the text content of the webpage is important and not the structural information of the page.
- Input:
url(string) - Returns: Markdown content of the URL
Setup
API Key (optional)
Optionally get an API key from the ScrAPI website.
Without an API key you will be limited to one concurrent call and twenty free calls per day with minimal queuing capabilities.
Cloud Server
The ScrAPI MCP Server is also available in the cloud over SSE at https://api.scrapi.tech/mcp/sse and streamable HTTP at https://api.scrapi.tech/mcp
Cloud MCP servers are not widely supported yet but you can access this directly from your own custom clients or use MCP Inspector to test it. There is currently no facility to pass through your API key when connecting to the cloud MCP server.
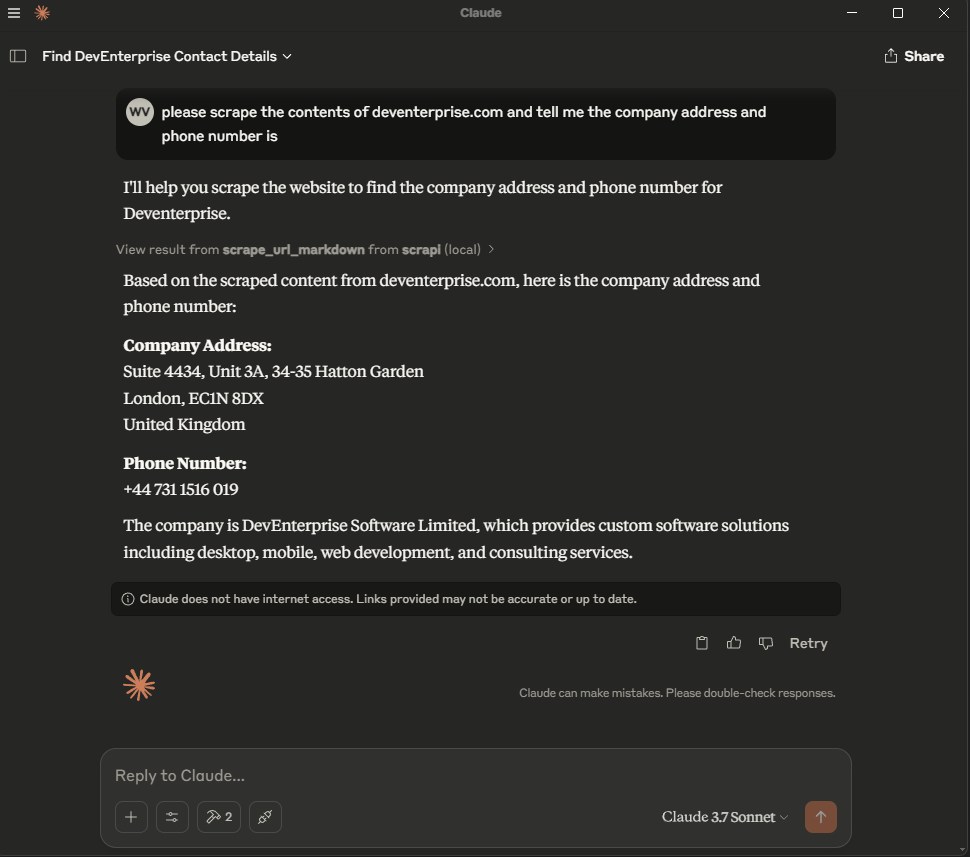
Usage with Claude Desktop
Add the following to your claude_desktop_config.json:
Docker
{
"mcpServers": {
"ScrAPI": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-e",
"SCRAPI_API_KEY",
"deventerprisesoftware/scrapi-mcp"
],
"env": {
"SCRAPI_API_KEY": "<YOUR_API_KEY>"
}
}
}
}
NPX
{
"mcpServers": {
"ScrAPI": {
"command": "npx",
"args": [
"-y",
"@deventerprisesoftware/scrapi-mcp"
],
"env": {
"SCRAPI_API_KEY": "<YOUR_API_KEY>"
}
}
}
}
Build
Docker build:
docker build -t deventerprisesoftware/scrapi-mcp -f Dockerfile .
License
This MCP server is licensed under the MIT License. This means you are free to use, modify, and distribute the software, subject to the terms and conditions of the MIT License. For more details, please see the LICENSE file in the project repository.
Scrapi MCP Server Reviews
Login Required
Please log in to share your review and rating for this MCP.
Similar MCP Servers like Scrapi MCP Server
Explore related MCPs that share similar capabilities and solve comparable challenges
Fetch
Officialby modelcontextprotocol
A Model Context Protocol server that provides web content fetching capabilities.
Playwright MCP
Officialby microsoft
Provides fast, lightweight browser automation using Playwright's accessibility tree, enabling LLMs to interact with web pages through structured snapshots instead of screenshots.
Firecrawl MCP Server
by firecrawl
Provides powerful web scraping capabilities for LLM clients such as Cursor, Claude, and others, enabling content extraction, crawling, search, and batch processing through a Model Context Protocol server.
Firecrawl MCP Server
by firecrawl
Provides web scraping, crawling, search, and structured data extraction for LLM clients through a Model Context Protocol server.
Web MCP
Officialby brightdata
Provides real-time web access for AI models, delivering search, markdown‑ready scraping, and optional browser automation while bypassing geo‑restrictions, rate limits, and CAPTCHAs.
Tavily MCP
by tavily-ai
Provides real‑time web search, intelligent data extraction, structured website mapping, and systematic crawling through an MCP server, ready to be integrated with AI coding assistants and other tools.
Fetch MCP Server
by zcaceres
Fetches web content and returns it in HTML, JSON, plain‑text, or Markdown formats, optionally applying custom request headers.
Hyperbrowser MCP Server
by hyperbrowserai
Provides tools to scrape, extract structured data, crawl webpages, and access general‑purpose browser agents such as OpenAI CUA, Anthropic Claude Computer Use, and lightweight Browser Use via a Model Context Protocol server.
AgentQL MCP
Officialby tinyfish-io
Extract structured data from any web page by invoking AgentQL's extraction tool through a Model Context Protocol server, enabling AI assistants to retrieve and format web information on demand.